Skills Are Context, and Context Needs Tests
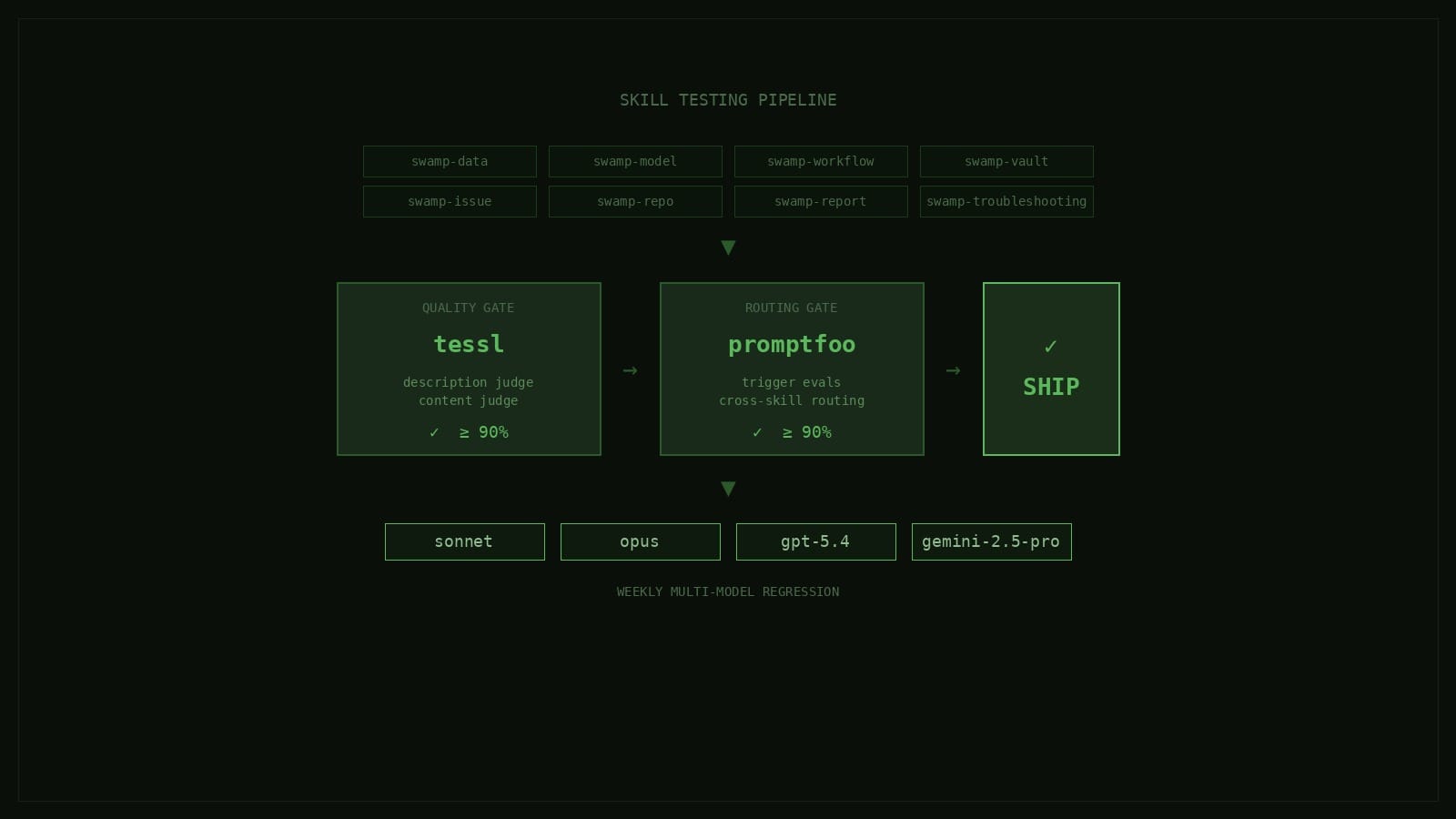
Skills are context. They're the thing an agent reads before it decides how to use swamp. If the skills are wrong, everything downstream is wrong — so we test them in CI the same way we test code, using tessl for quality and promptfoo for routing, across every model we care about.
When we talk about swamp, most people assume the most importany part is the CLI, the extension model, or the datastore. The part we actually spend a bunch of time on is none of those. It's the set of swamp-* skills that ship inside with the swamp binary and tell an agent how to use it.
Skills are context. They are the thing an agent reads before it decides whether to touch your datastore, run a model method, debug a workflow, or leave you alone. If the skills are wrong, everything downstream is wrong, and it doesn't matter how good the CLI is underneath. So we treat them the same way we treat code: they live in the repo, they get reviewed in PRs, and they get tested in CI on every change.
This post walks through how we think about that, and specifically how we use promptfoo and tessl to make sure the skills we ship actually do their job.
What we mean by "skills"
Every swamp install comes with a set of skills under .claude/skills/swamp-* (or your agent specific setup) . There's swamp-data for managing model data, swamp-model for working with models themselves, swamp-workflow for building and running workflows, swamp-issue for the issue lifecycle, swamp-vault for secrets, swamp-troubleshooting for when things go wrong, and many more. Each one is a directory with a SKILL.md file that contains YAML frontmatter (a name and a description) and a body of instructions.
At runtime, the agent loads skills progressively. It sees every skill's name and description in the system prompt by default, that's about 100 words of metadata per skill. When a user query matches a description, the agent loads the full SKILL.md body into context. If that body references detail files in references/, the agent loads those on demand.
The part that matters most is the description. It's the trigger mechanism. If the description doesn't match the user's phrasing, the skill never loads, and the agent answers from general knowledge instead of the specific context we wrote for swamp. A subtly wrong description is worse than a missing one, because it either fires when it shouldn't or stays silent when it should help.
Two questions, two tools
Testing a skill means answering two separate questions.
The first is "is the skill itself well-written?": is the description specific enough, does the body use imperative voice, does it avoid duplicating trigger guidance into the body, does it follow the structural conventions we care about. This is a quality question about the text of the skill in isolation.
The second is "does an agent actually route to this skill when it should, and stay away when it shouldn't?": this is a behavioral question about how the skill interacts with every other skill in the system. A skill can be perfectly written and still lose to a neighbor whose description happens to overlap.
We use two different tools for these two questions, and we run both.
Tessl for quality
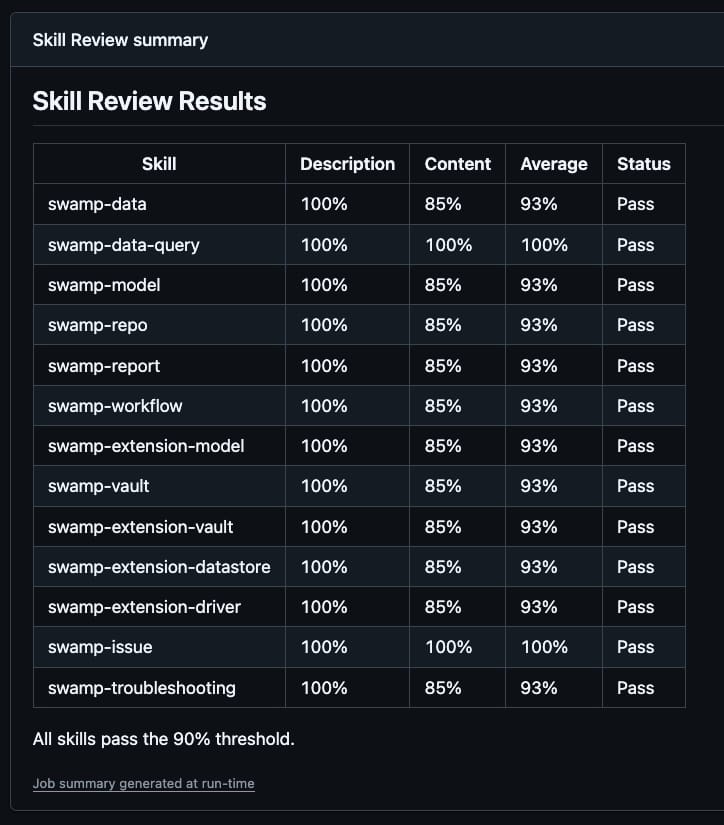
Tessl reviews the structural quality of a SKILL.md by scoring its frontmatter description and its body against a set of authorship rules. It returns three numbers: a validation check (frontmatter format, naming conventions), a description judge score between 0 and 1, and a content judge score between 0 and 1. We require the average of the description and content scores to be at least 0.90. Anything lower either fails CI or gets flagged in review.
Running it against one skill looks like this:
npx tessl skill review .claude/skills/swamp-data --jsonWe have a wrapper task, deno run review-skills, that runs tessl across every swamp skill in .claude/skills/ and prints a summary table. In CI, that table goes straight into the GitHub Actions step summary so whoever is reviewing the PR can see at a glance which skills changed scores.
Promptfoo for routing
Our Tessl check doesn't answer "will the agent actually pick this skill for the right query." That's a question about how the skill behaves next to every other skill, and the only honest way to answer it is to hand a realistic query to a real model and check which skill it calls.
That's what promptfoo does. Every skill has an evals/trigger_evals.json file that contains a list of test cases, each a realistic user query paired with an expected routing decision. Something like:
[
{ "query": "Show me all the model data currently stored in swamp", "should_trigger": true },
{ "query": "List the version history for the Customer model", "should_trigger": true },
{ "query": "Create a new workflow to run tests nightly", "should_trigger": false }
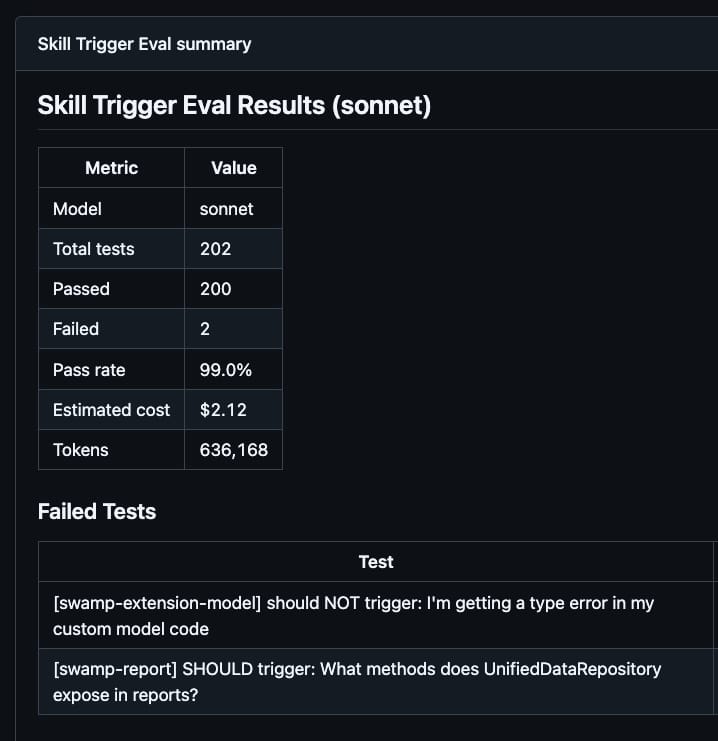
]The positive cases check the skill fires when it should. The negative cases are the ones that actually catch regressions, they check the skill doesn't fire on queries that should route to a neighbor. Every time we add a new skill or tweak a description, we add a handful of negative cases pointing at the skills it's most likely to conflict with.
Promptfoo reads every trigger_evals.json file, presents each query to the configured model as a tool-selection task, and asserts the correct routing decision. We run it with deno run eval-skill-triggers, and the default threshold is 90% pass rate. A sonnet run costs around $2 and takes about 30 seconds.
Both gates run on any PR that changes skills
CI has a change-detection filter that watches .claude/skills/**, CLAUDE.md, the review_skills.ts script, and the evals/promptfoo/** config. Any PR that touches one of those runs two jobs in parallel:
skill-review runs deno run review-skills and fails the PR if any skill scores below 90% on tessl.
skill-trigger-eval runs deno run eval-skill-triggers against the default sonnet model and fails the PR if the routing pass rate drops below 90%.
Both jobs write their detailed results to the GitHub Actions step summary, so the author doesn't have to dig through log output to understand what regressed. A skill that drops from 96% to 88% on tessl shows up in the summary table with a red delta. A promptfoo run that starts misrouting "list the version history for my model" to swamp-model instead of swamp-data shows up as a failed assertion with the exact query that tripped it.
Once both pass, along with the usual code review and tests, the PR auto-merges.
Weekly multi-model regression
The PR check only runs against one model (sonnet) because running every PR against four models every time would get expensive fast. But we still care about whether a tweak to a description quietly broke routing on opus, or gpt-5.4, or gemini-2.5-pro.
So we have a scheduled workflow that runs every Saturday at 08:00 UTC. It runs the full promptfoo suite against four models in parallel:
| Model | Provider | Concurrency |
|---|---|---|
| sonnet | Anthropic | 20 |
| opus | Anthropic | 20 |
| gpt-5.4 | OpenAI | 5 |
| gemini-2.5-pro | 20 |
The reason we run against four models instead of one is that we're actively trying to make swamp skills useful across every major agent tool and the primary models those tools ship with. A skill that routes perfectly on sonnet but falls over on gpt-5.4 isn't a skill we're willing to ship, because the person using swamp through a gpt-5.4-backed agent deserves the same experience as the person using it through sonnet. The weekly cadence is a tradeoff between cost and catching drift fast, and it gives us a consistent pulse on whether any of those models has started to drift away from the others.
The workflow can also be triggered manually with a model filter, which is what we do when we're actively tuning a contentious description and want faster feedback than the weekly cron.
Why this matters
The thing we learned the hard way is that skills drift. You write a description that routes perfectly at the time you wrote it, and then six months later someone adds a neighboring skill, or a model provider tweaks how their tool-selection logic works, or a new phrasing of the same question becomes common, and suddenly your skill is firing on the wrong queries or not firing at all. Without tests, you find out by watching an agent confidently fail to use the tool you already built.
Treating skills as context means treating them with the same rigor as code. They go in the repo. They get reviewed in PRs. They fail CI when they're broken. They get a weekly regression suite against every model we care about. And because swamp is the system we use to build swamp, every improvement to a skill is tested on the next task we use it for, which is often a task that involves editing another skill.
We don't ship a skill because it reads well. We ship it because it passes both tests, against every model, every week. That's the bar.