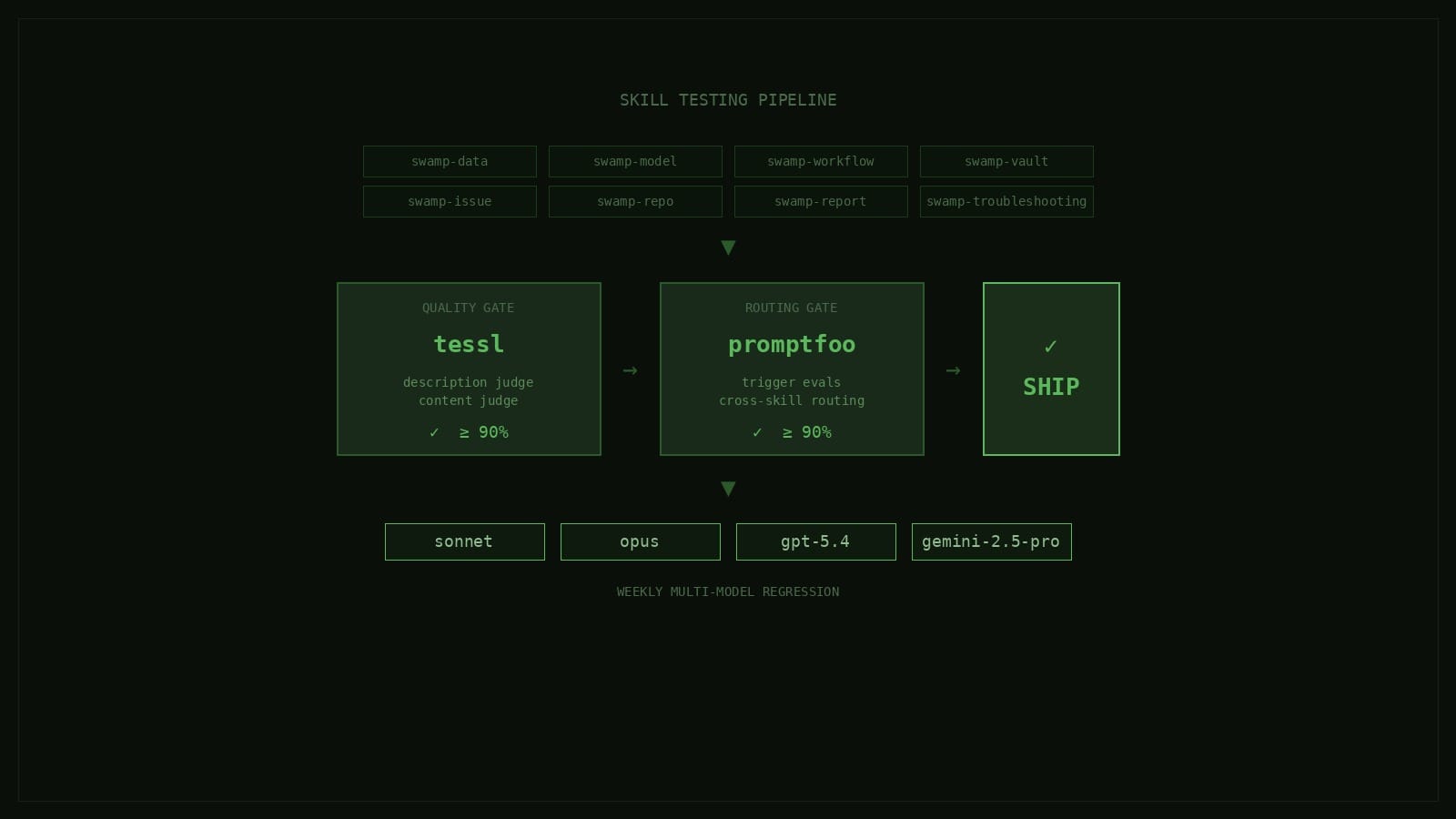
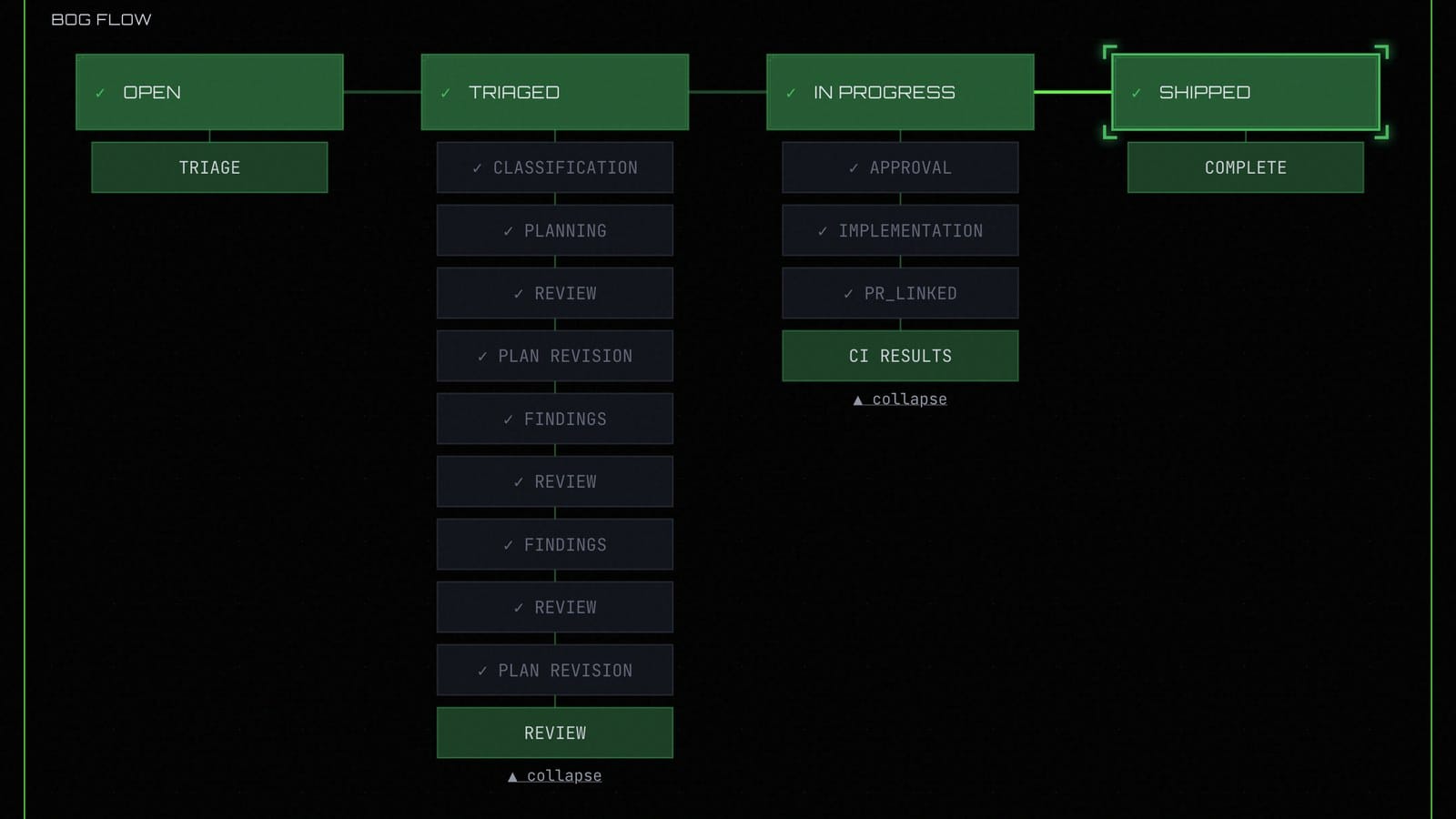
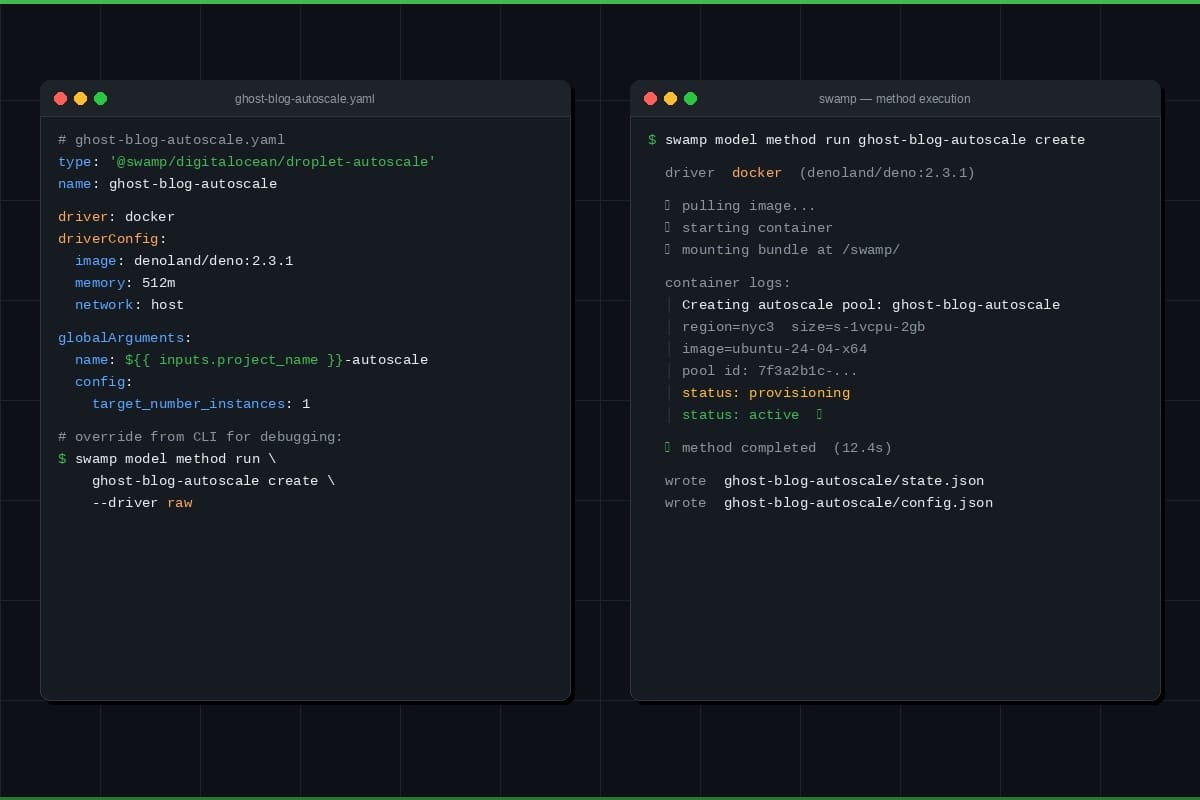
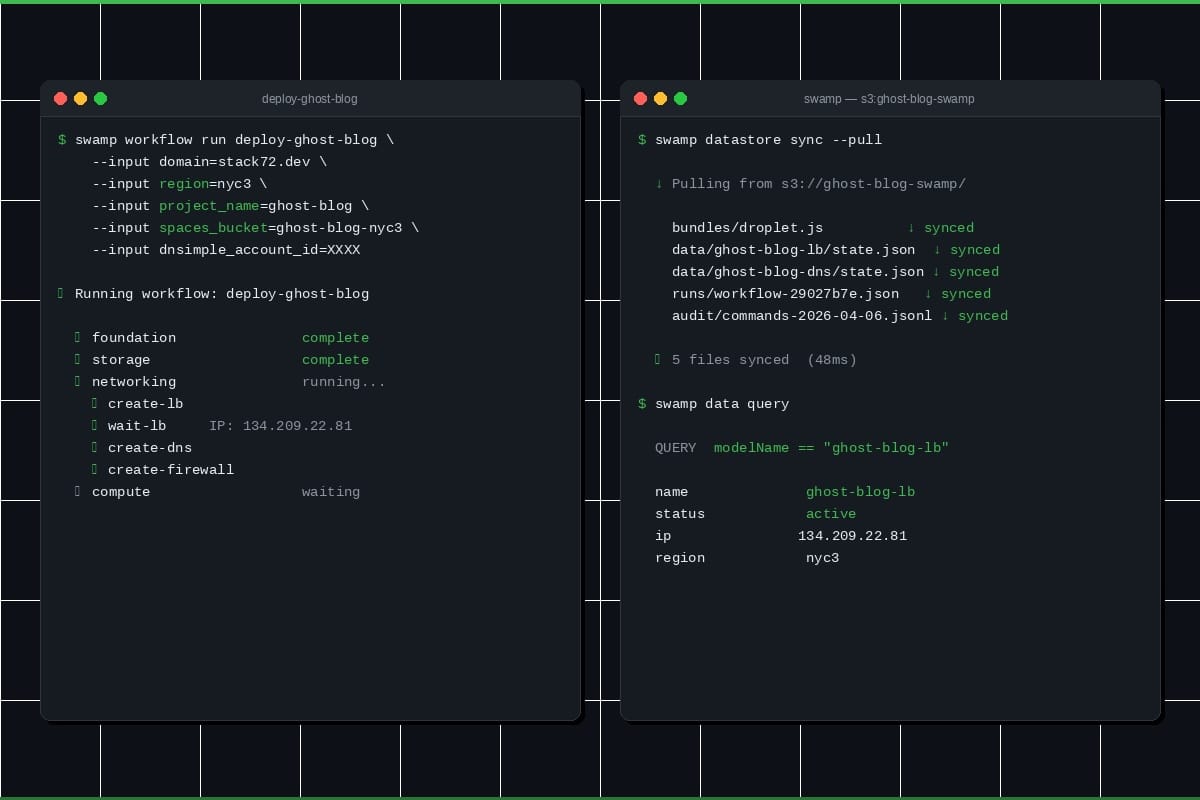
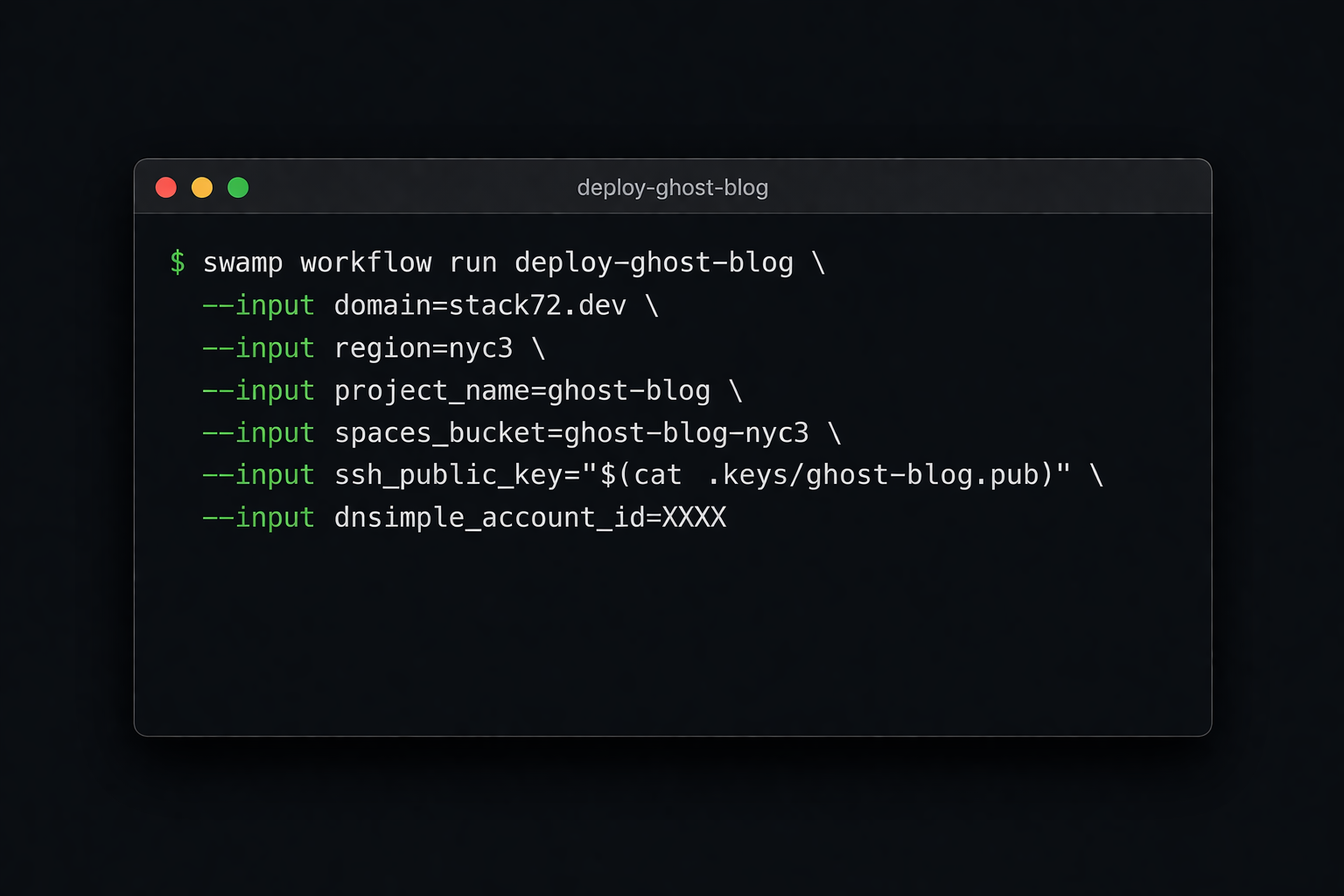
Infrastructure was the first use case we looked at with swamp. Then users started solving security, finops, and validation problems with the same model. By the fifth time, it was hard to treat it as a coincidence. We'd built an automation primitive, and infrastructure was just where we'd pointed it.