The Lifecycle of a Swamp Issue
We use swamp to build swamp. That sounds like marketing until you look at how an issue actually moves through our process — not as a GitHub thread with comments piling up, but as a state machine with versioned plans, adversarial reviews, and checks that refuse to let the agent skip steps.
We use swamp to build swamp. Not in the loose "we dogfood our tool" sense, but literally: the lifecycle that takes a swamp issue from filed to shipped is itself a swamp model, running on swamp, built and maintained using the same process it governs.
An issue in swamp isn't a GitHub thread with comments piling up until someone closes it. It's an instance of a model called @swamp/issue-lifecycle, with a state machine, versioned resources, and checks that gate every transition. The human steers and the agent executes, but every meaningful step is a method call that writes data the next step can read.
That model didn't appear out of thin air. We built it by watching how we actually worked with agents on features and bug fixes over and over again — the same loop of triaging, exploring the codebase, drafting a plan, tearing it apart, iterating, and finally implementing. Once the shape of that loop was obvious, we encoded it as a swamp extension model so the process our agents went through became the process, enforced in code rather than remembered in a prompt.
The model is the lifecycle
At a glance, an issue flows through five phases:
- Triage. The issue is fetched from swamp-club, the agent reads the codebase and reproduces any bug, then classifies it as a bug, feature, or security item.
- Planning. The agent drafts an implementation plan against the repo's planning conventions, breaking down steps, files, testing strategy, and risks.
- Adversarial review. The plan is immediately torn apart across repo-specific dimensions and findings are recorded with severities.
- Iteration. The human gives feedback, the agent revises the plan, the review runs again. This loops until the plan is clean and the human approves it.
- Implementation. Only after approval does the agent start doing the work, and only after the work is done and verified does the lifecycle reach complete.
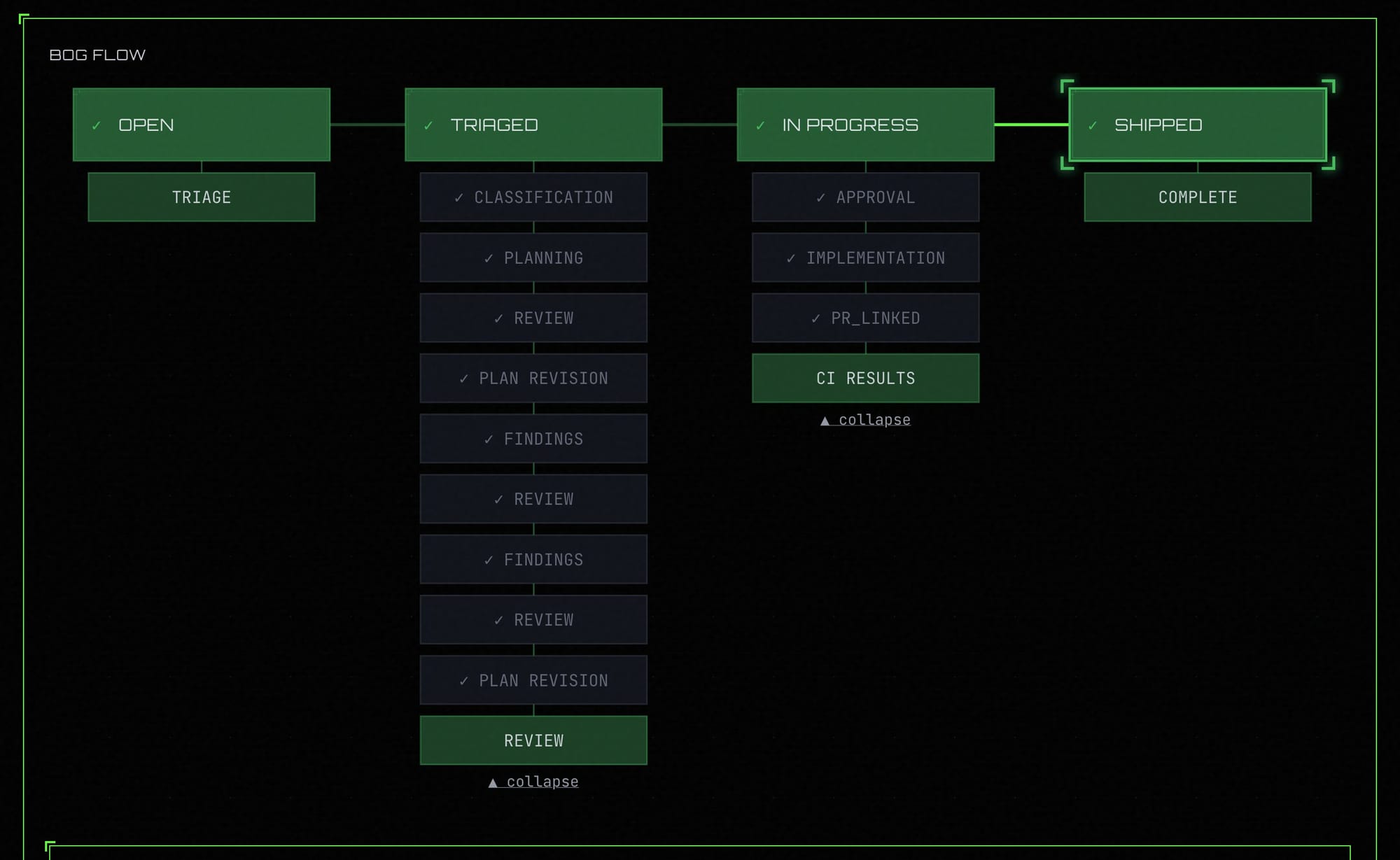
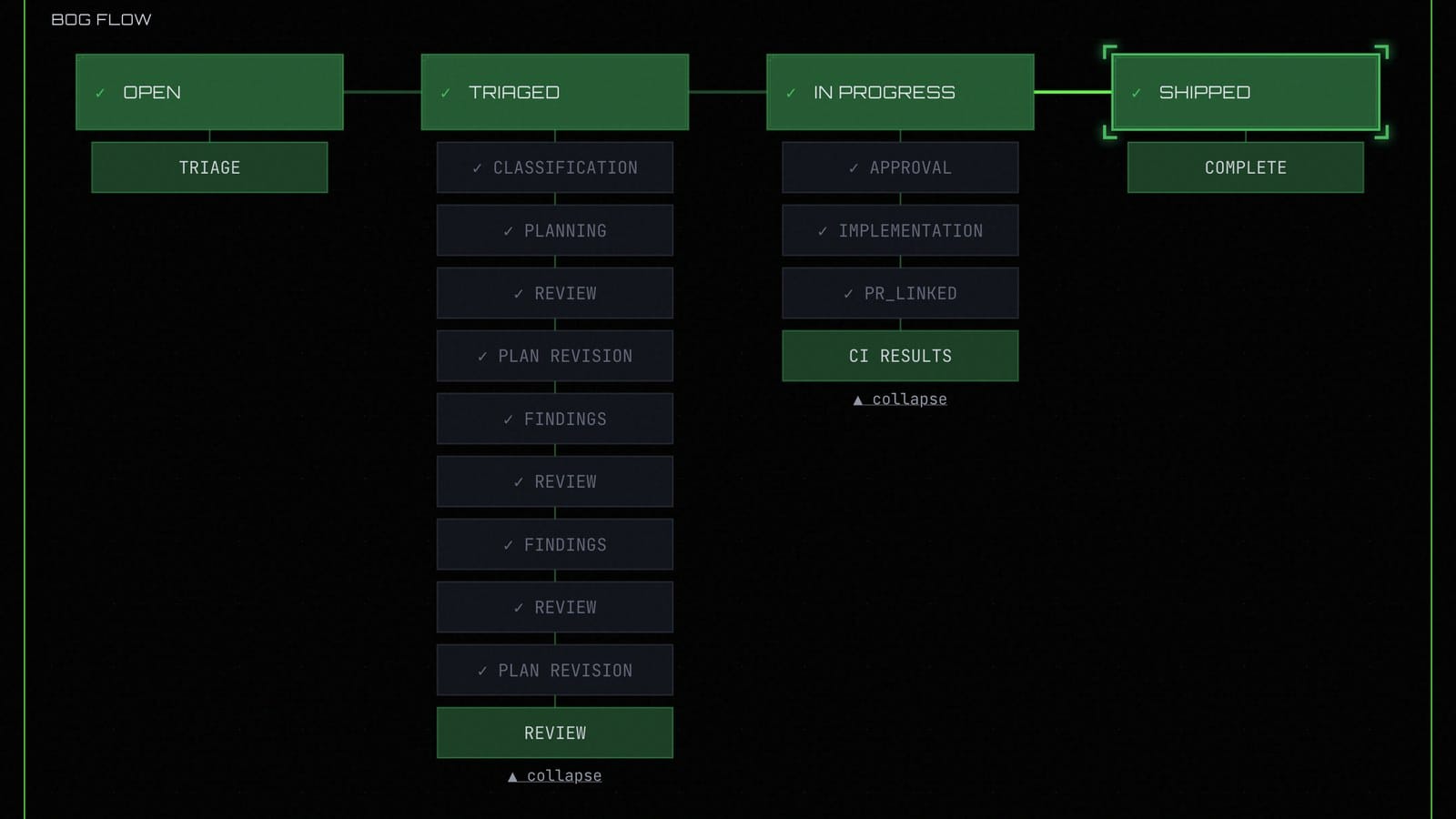
The image above is the same flow as it actually appears in swamp-club. You can see the four top-level statuses (OPEN, TRIAGED, IN PROGRESS, SHIPPED) across the top, and underneath each one the agent event stages that fire during that phase — classification, planning, review, plan revision, findings, approval, implementation, PR linking, and so on. Every one of those sub-entries is a method call in the model that wrote data and posted a lifecycle entry to swamp-club as part of the same step.
Underneath that flow, the extension model stores everything it needs to remember. Each issue has a context resource for what swamp-club said about it, a classification for the triage decision, a versioned plan for every iteration of the implementation plan, a feedback record for every round the human gave notes, an adversarialReview for the findings against the current plan version, and a state resource tracking which phase the issue is currently in.
The methods (start, triage, plan, review, iterate, adversarial_review, resolve_findings, approve, implement, complete) are the transitions between phases, and every one of them is guarded by checks. You can't call approve if no plan exists, if the plan hasn't been adversarially reviewed against its current version, or if any critical or high findings are still unresolved. implement is blocked until the plan is approved. And calling anything in the wrong phase just bounces.
The state machine isn't a convention written in a markdown file somewhere. It's running code that refuses to transition if the prerequisites aren't met, which means the agent physically cannot skip steps.
An agentic flow doesn't fit GitHub
As we built this process out, we quickly realised that trying to retrofit it into a GitHub issue wasn't working. Phase transitions, plan versions, findings, feedback rounds — they all turned into yet another comment, and the signal got buried under the noise.
GitHub issues were fine when the lifecycle of an issue was "someone writes a comment, someone else reads it, eventually a PR shows up." That model breaks down the moment your lifecycle includes structured state like plan versions, review findings, feedback rounds, and phase transitions. You end up stuffing JSON into hidden comments, abusing labels as a state machine, and praying nobody clicks the wrong button.
We tried keeping GitHub as the system of record and posting rich comments at each stage. It worked, but GitHub was fundamentally read-only to the agent. The real state lived in the swamp datastore and GitHub was just a reflection of it for humans to read. That's backwards, and two systems claiming to track the same thing is two systems you have to keep in sync.
So we cut GitHub out of the loop. Swamp-club is now the source of truth, and it's itself a swamp model. Every method call in the issue-lifecycle model posts a structured lifecycle entry to swamp-club and transitions the issue's status as part of the same step. Triage started. Classified as bug. Plan generated v1. Adversarial review, two high and one medium. Plan revised v2. Findings resolved. Plan approved. Implementation started. Complete.
Those entries are agent event stages, not human-authored comments. The stages are the lifecycle. There's no separate layer where someone needs to update the issue because the update is the work.
What you actually get
Resumability stops being a feature you have to think about. An agent can drop in halfway through, run swamp model get issue-N --json, and see exactly where things are and what the next valid transition is. Because the checks are enforced at the model level, it can't get it wrong even if the conversation context is gone.
Auditability is just the datastore. Plan versions, feedback rounds, findings, state transitions — they're all data records with a timestamp. If you want to know why a particular decision was made, the reasoning is there. In practice we use this more than we thought we would, usually to go back and figure out which round of feedback actually fixed a gnarly edge case.
And because every repo can drop its own files into agent-constraints/, the lifecycle adapts to the project without changing the model. The planning conventions for swamp itself look nothing like the planning conventions for a Rails app, but the model doesn't care. It just asks the agent to read the conventions and follow them.
Triage starts with an operator
When someone files an issue in swamp-club (our lab issue tracker), nothing happens automatically. An operator kicks off the lifecycle by telling the agent to start working on a specific issue, which calls start, fetches the issue, writes the context resource, and moves the state to triaging.
We do this deliberately for two reasons. The first is prompt injection. If any agent could pick up any issue the moment it was filed, the issue body becomes an attack surface — anyone who can open an issue can feed instructions straight into an agent. Requiring an operator in the loop means a human has already decided this issue is worth working on before any agent reads a word of it. The second reason is judgment. The operator who starts the work is usually the person who will live with the outcome, and having them see the issue before the agent does shapes the framing of everything that follows. Context set by a human tends to produce better plans than context set by a ticket template.
From there the agent reads the repo, reproduces the bug if there is one, and calls triage with a type, a confidence level, and reasoning. That writes the classification and transitions the phase to classified. If the agent can't classify confidently it doesn't guess. It sets confidence to low, records clarifying questions, and waits for the human before moving on.
Planning is paired with adversarial review
Once triaged, the agent generates a plan by calling the plan method. Before doing that, it reads agent-constraints/planning-conventions.md from the repo. That file lives in every swamp repository and tells agents what a good plan looks like for that specific codebase — domain-driven design analysis, file-level breakdowns, testing strategy, risks. The plan goes into a versioned resource, so every iteration is preserved.
Then the agent immediately runs adversarial_review. This isn't optional. The skill instructions say adversarial review is always paired with plan generation, and the checks enforce it at the model layer. The review calls out weaknesses across dimensions the repo defines in agent-constraints/adversarial-dimensions.md and writes findings with severities attached.
If there are critical or high findings, the plan cannot be approved. The adversarial-review-clear check blocks it. The only way forward is to iterate the plan, which bumps the plan version and triggers another review round. The plan at v4 knows about the feedback from rounds 1, 2, and 3 because the feedback is all living in the datastore.
The human stays in the loop on purpose
The core rule during planning is simple: never auto-approve. The agent is not allowed to decide on its own that a plan is good enough. It generates, reviews, presents, and waits. The human reads it and either gives feedback (which calls iterate with a revised plan) or says to proceed (which calls approve).
That rule is specific to the planning phase. Once the plan is approved and the work moves into implementation, a separate process takes over and checks the outputs the agent produces against the plan it signed up to deliver. We'll cover how that works in a follow-up post — it's a whole story on its own.
Every iteration and every feedback round is preserved. Nothing gets lost in a scrollback buffer because nothing lives in a scrollback buffer.
Dogfooding all the way down
This is what we mean when we say we use swamp to build swamp. The issue lifecycle isn't a script we wrote once and forgot about. It's a swamp model living in loaded into the repo as an extension, governed by the same checks and datastore semantics as any other model. When we want to change how triage works, we edit the issue-lifecycle extension and the upgrade system carries old instances forward. When we want to change what a good plan looks like, we edit a file in agent-constraints/.
The lifecycle of a swamp issue is a swamp workflow, running on swamp infrastructure, built and maintained using swamp. Any improvement we make to the model — a new check, a new phase, a new constraint — gets tested on the next issue we work on, which is usually the next improvement to the model itself. The feedback loop is tight enough that the tool gets sharper every time we use it.
If the tool can't handle its own process, it isn't ready to handle yours. Ours does, and that's the bar we're holding it to.