The Gate Between Our Agent Code and Our Users
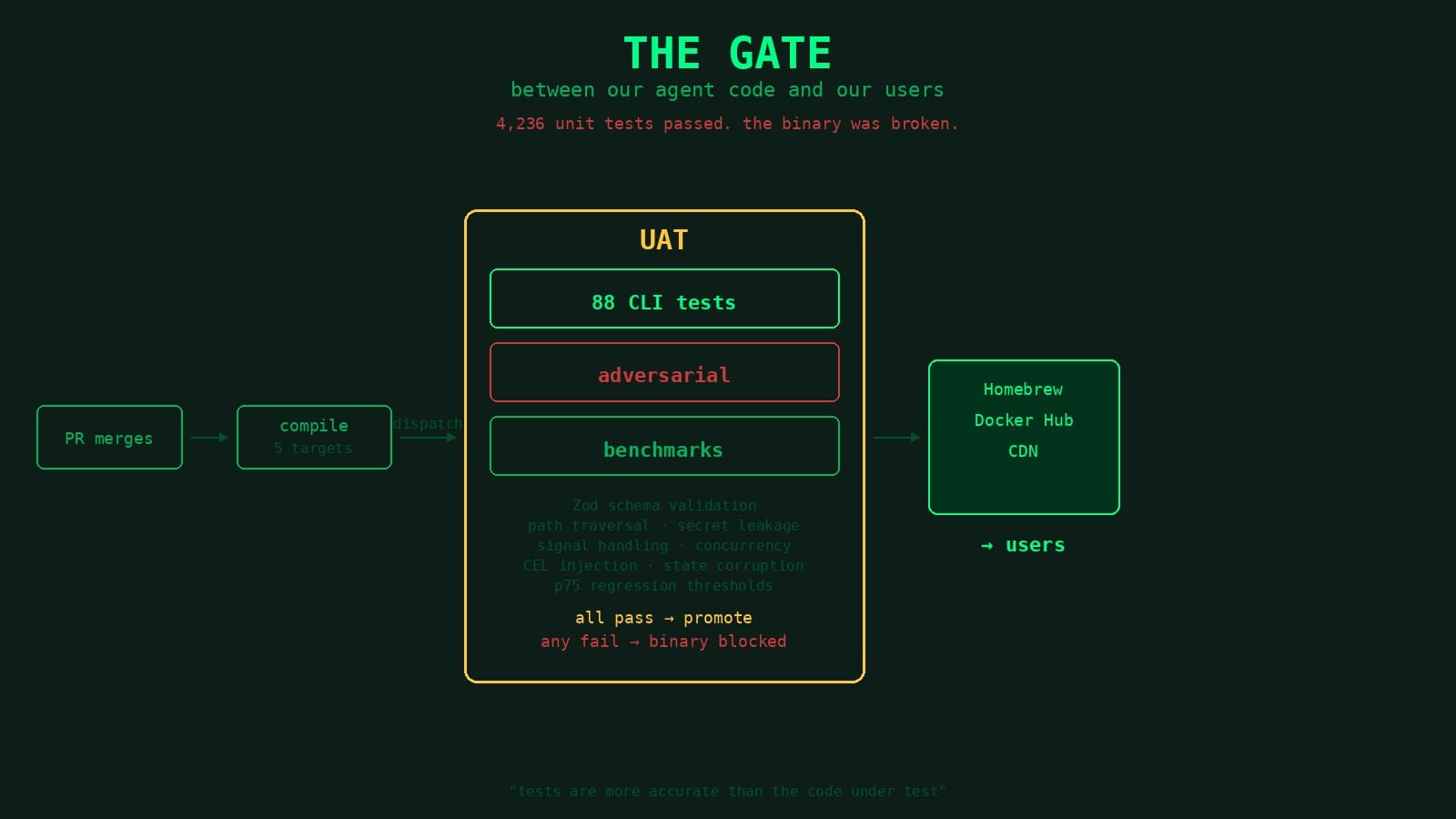
Every release binary gets dispatched to a separate repo running CLI tests, adversarial security tests, and benchmarks. Three recent bugs — all with full unit test suites passing — never reached a user because the UAT caught them in minutes.
We test our code but we also test the thing users actually download.
When a PR merges in the swamp repo, the release workflow compiles cross-platform binaries, creates a GitHub release, and fires a repository dispatch to a separate repo — swamp-uat. That repo downloads the exact binary from the release and runs it through CLI acceptance tests, adversarial security tests, and performance benchmarks. If anything fails, the binary doesn't get promoted to stable and we don't get a release pushed to Homebrew or Docker Hub.
The swamp repo has its own tests: unit tests, contract tests, architectural fitness tests, property tests. Those run on every PR before merge. But they run against source code. The UAT suite runs against the compiled artifact. Different thing.
We call it UAT deliberately. Not in the modern "QA team runs through a checklist" sense but in the original sense. User acceptance testing. Every test is written from the perspective of someone using the CLI. It creates a real repo, runs real commands against the real binary, checks the output a user would actually see. If a test calls swamp vault create, it's doing exactly what a user would type. If the structure of the output changes, the test fails because the user's experience changed. The tests don't care about internal implementation. They care about what happens when you run the binary. Name stuck.
The dispatch
When the PR merges the release workflow stamps a version like 20260415.234530.0-sha.a1b2c3d4, compiles for five targets (linux x86_64, linux aarch64, macOS x86_64, macOS aarch64, windows x86_64) creates the release, then fires a repository dispatch:
- name: Trigger UAT
uses: peter-evans/repository-dispatch@v3
with:
token: ${{ secrets.UAT_TRIGGER_TOKEN }}
repository: systeminit/swamp-uat
event-type: run-uat
client-payload: '{"version": "${{ steps.version.outputs.version }}"}'
swamp-uat picks up the event, downloads that exact binary, and starts running.
Three bugs the UAT stopped from shipping
Before getting into the test layers, here's why they exist. These are all real, all recent, and they all have the same shape: unit tests green, bug at an integration seam, UAT caught it in minutes. In every case, the binary never made it to stable — no user ever saw the bug.
Silent data loss in workflows
On April 8th, PR #1145 merged. This was a refactor that promoted provenance to first-class DataRecord fields and switched data.latest(), findByTag(), findBySpec(), and query() from synchronous filesystem reads to async DataQueryService queries. All 4,236 unit tests passed.
Four minutes later, the UAT run failed. Two tests in vary_dimensions_test.ts — both trying to read data inside a workflow using data.latest(...).attributes.*. The error: Invalid expression: No such key: attributes. Every expression silently returned nothing.
DataQueryService had been added to ModelResolver but was never wired into the workflow execution paths. The refactor's unit tests exercised the service in isolation. Nobody thought to check whether workflows could actually reach it. Every multi-environment workflow that read prior data would have produced incorrect output with no error. Silent data loss.
Fix merged four hours later. The fix PR cites both failing UAT tests by name.
Every user-defined vault broke
On April 6th, PR #1089 merged: This was a lazy-per-bundle loading optimization for vault, driver, datastore, and report registries. CLI startup improved by 55% on subsequent runs. All 4,159 unit tests passed.
Three minutes later, UAT failed 11 tests across two files. Every one reported the same thing: Error: Unknown vault type: @test/mock-vault. Available types: local_encryption. The only vault type that worked was the hardcoded built-in one.
First assumption was that the extension wasn't being loaded at all, some bundling issue. Took a while to realize the type was indexed, just not imported. The new lazy-loading split each registry into two maps, types (fully imported) and lazyTypes (indexed but not yet imported). has() checked both maps. get() only checked types. So if (registry.has(type)) passed, but get() returned undefined. Eleven call sites had the same bug. Easy to miss in review because has() and get() are two lines apart and both look correct on their own.
Every swamp user with a third-party vault, AWS Secrets Manager, Azure Key Vault, 1Password, or a custom datastore would have been locked out of their own secrets on upgrade. A performance win would have shipped as a complete feature outage for anyone using the extension system. Which is essentially every production deployment.
Fix merged 66 minutes later. 15 files changed, 11 call sites patched.
A regression on top of a fix
On April 20th, PR #1197 merged. This was a tri-state inspectInstallation check to detect truncated extension installs. The check stat'd every path in the lockfile, including compiled bundle caches under .swamp/bundles/**.
UAT failed on pull_wip_preservation_test.ts. The test simulates something real: a developer pulls an extension, edits the source to add work-in-progress changes, clears .swamp/bundles (routine rebuild hygiene), and tries to use the extension. The expected experience is a helpful recovery hint telling you local edits may be preventing the extension from loading and offering a --force flag to reset. The actual experience after #1197: incomplete — missing 1 file(s): ".swamp/bundles/91139983/system_usage.js". No guidance, no recovery path.
That recovery hint was a feature the UAT was specifically written to protect. The test was written once. It kept silently earning its keep, catching a later, well-intentioned fix that accidentally regressed the user-facing contract. Unit tests for the new PR passed. Only an end-to-end test that actually pulled an extension, edited its source, cleared the cache, and checked the error message could have noticed.
Fix merged 72 minutes later. The truncation check now scopes to source files only, bundle caches are regenerable build artifacts, not evidence of a broken install. Without the UAT gate, that binary would have gone to stable and every user who cleared their bundle cache after editing an extension would have lost the recovery hint. They'd have been staring at a cryptic missing-file error with no way forward.
CLI acceptance tests
88 test files. Every CLI command has its own test file, and the file path mirrors the command path — swamp vault list-keys lives at tests/cli/vault/list_keys_test.ts. Each test gets its own empty temp directory, runs the binary, checks the output, validates exit codes.
Every command gets tested with its global flags, --json, --quiet, --verbose, --help. Not just "does the command work" but "does every flag combination users rely on produce the right output in the right format."
JSON output gets validated against Zod schemas. The actual shape, fields, types, format patterns. If a model validate command returns warnings, we check that each warning has a name, a message, and an envVars array with path and envVar fields. Schema drifts, test fails.
The pattern:
Deno.test("swamp vault create creates a local encryption vault", () =>
withRepoContext(async (repo) => {
const result = await runJsonCommand(
runner, ["vault", "create", "local_encryption", "my-vault"], repo.dir,
VaultCreateSchema
);
assertEquals(result.name, "my-vault");
assertEquals(result.type, "local_encryption");
await waitFor(() => assertEquals(instance.hasExit()?.exitCode, 0));
}));
withRepoContext creates an isolated temp directory and cleans it up. runJsonCommand runs with --json, parses the output, validates against the Zod schema. waitFor retries the exit code assertion until the process finishes.
Adversarial tests
We don't just test that things work, we test what happens when someone tries to break them.
Path traversal. model create command/shell ../../etc/passwd needs to be rejected. vault create local_encryption ../../../tmp/evil needs to be rejected. Every command that takes a name gets tested with traversal payloads. We check that extracted extension archives can't escape the repo boundary, and that symlinks in extension directories don't point outside.
Secret leakage. A model resolves a vault secret, then the command fails. Does the secret appear in stdout? In stderr? In verbose mode? We set AWS_SECRET_ACCESS_KEY in the environment and run commands with --verbose and the value must never appear in output. JSON error output can't include stack traces. The redaction boundary is deliberate, secrets under 3 characters aren't redacted to avoid false positives on values like "no." Three characters or more, always redacted.
CEL injection. Our expression language supports vault resolution and data queries. We throw file.read('/etc/passwd'), exec('whoami'), runtime.exec('id') at it to ensure none execute and none expose system files.
Signal handling. Kill a vault put mid-write with SIGTERM. Is the vault still consistent? The stored value is either the original or the new value, never a partial write, never corrupted. This test exists because a user reported corrupted vault state after a Ctrl-C. The fix was atomic file writes (temp file, then rename) but the test is what proves it holds.
Stale locks. SIGKILL a process that holds a lock file. The next command should detect the dead PID and reclaim within 5 seconds. We had an agent sit for 45 seconds waiting on a lock that would never be released. The lock reclaim logic came from that.
Concurrent operations. Five simultaneous model method runs and each gets a distinct version number. Five parallel vault puts to the same key, last-write-wins is fine, corruption isn't. Three concurrent workflow runs producing data to the same name and exactly one gets marked latest.
Resource exhaustion. A model producing roughly 100MB of stdout. Completes without OOM, creates at least one data version.
State corruption. Truncate .swamp.yaml to empty. Replace it with {{{not valid yaml. Delete it entirely. Replace a model definition with garbage. Make the .swamp directory read-only. In every case: fails gracefully, no panic, clear error message.
Performance benchmarks
Four benchmark suites: datastore, extensions, models, vaults. Each runs 2 warmup iterations (discarded), then 5 measured. We compute p50, p75, p95. The p75 has to stay under a threshold.
vault put— p75 under 2500msextension pull(cold) — p75 under 10000msextension pull(warm, re-pull same version) — p75 under 5000msmodel method run— p75 under 5000msdatastore sync --push— p75 under 3000ms
There's a SWAMP_BENCH_THRESHOLD_MULTIPLIER for scaling thresholds on slower CI runners. Baselines are set against what a user would actually experience.
We don't benchmark to prove we're fast. We benchmark to catch regressions. A refactor adds 800ms to vault operations, we want to know before it ships.
Tests are the source of truth
This is the rule that holds the whole thing together: the tests are more accurate than the code under test.
When a UAT test fails, the assumption is that swamp has a bug. Not the test. The first line of the swamp-uat CLAUDE.md (the file every agent reads before it touches the repo) says it plainly:
Tests are more accurate than the code under test. When a test fails, the default assumption is that the swamp/swamp-club code needs to change, not the test. Never weaken, relax, or update a test to match current behavior unless the user explicitly asks you to update the UAT.
We enforce this hard because agents open most of the PRs. The failure mode is quiet. An agent changes how --json output is structured. The UAT test for that command fails. Another agent "fixes" the test by updating the Zod schema to match the new output. CI goes green. Nobody notices the output contract changed. Downstream tooling that parsed the old format breaks silently.
That's what happens without the rule, a slow accumulation of loosened assertions until your test suite is just confirming the code does what the code does.
Every time we find a new regression, we add UAT coverage for it. That's how the suite compounds.
The extension recovery hint test [above] is a good example. The original bug was straightforward, a user pulls an extension, makes local edits, and the CLI gave them a useless error instead of telling them what happened and how to fix it. We fixed the error message, added a --force flag for recovery, and wrote a UAT test that pulls an extension, edits the source, clears the bundle cache, and checks that the recovery hint appears. That test existed to protect one specific fix.
Months later, a completely unrelated PR landed, the tri-state truncation check from bug three above. Different author, different feature, nothing to do with extension recovery. But it changed how the CLI inspected extension installations, and that change accidentally broke the recovery path. The test failed but not because anyone thought to check, because the test was already there, silently protecting a contract nobody was thinking about anymore.
That's the pattern. Each bug we catch adds a test. Each test protects a user-facing contract. Over time, the surface area the suite covers grows, and the window for regressions to slip through shrinks. The suite gets harder to pass, which means the binary that does pass it is more trustworthy.
This is another part of the machine. The issue lifecycle shapes the work before code gets written. The PR pipeline reviews what comes out. The UAT gate stands between the compiled binary and the user.
Agents write ALL of our code. Agents open most of our PRs. The question people keep asking is "how do you trust the output?" This is how. Not by hoping the model gets it right but by building a gate that proves the binary works before any user ever sees it.